

Hi my dear readers! Ever since getting home from my book tour I’ve been thinking about taking on a new project. Recently I’ve been interested in learning about the math behind Artificial Intelligence (AI), so I’ve been taking the popular course on Coursera about Machine Learning by Andrew Ng.
To my surprise, the first machine learning algorithm we learned about was something I was already pretty familiar with, but I’ve never associated with AI: linear regression.
I learned a lot about it in my statistics classes in my undergrad, so I wanted to write this post to summarize the basics of linear regression, starting from scratch.
Imagine you’re a baby drag queen who’s only performed twice.
One of your performances was a 1 minute song where you collected $10 in tips,
Your other performance was a 3 minute song where you collected $30 in tips.
What is the relationship between performance length and tip amount?
Let's plot this data and look for patterns.
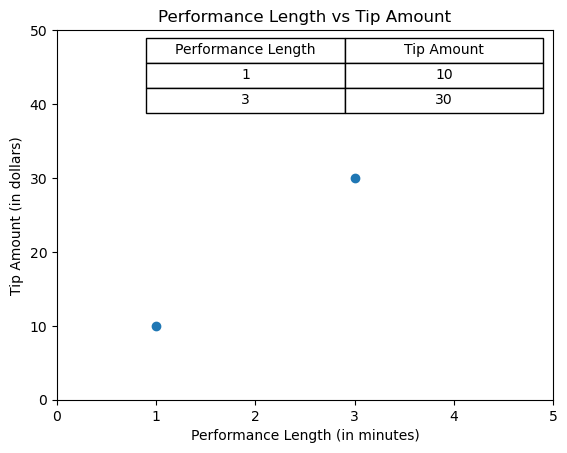
One pattern you might notice is that a shorter performance seems to mean fewer tips, and a longer performance seems to mean more tips.
Statisticians call this a *positive correlation*. When one variable rises, the other one also rises.
What if your next performance was somewhere in the middle: a 2 minute song?
How many tips could you expect to collect?
Less than 10 dollars? Between 10 and 30? Or more than 30?
If you answered “between 10 and 30”, then you’ve just hypothesized a linear relationship. You've done linear regression in your head!
You probably connected the dots in your head with a straight line and reasoned that if the performance length was somewhere in the middle between 1 and 3, then the tip amount should also be somewhere in the middle between 10 and 30, at around 20 dollars.

That’s linear regression in action!
Linear regression explores a possible linear relationship between our two variables,
x = performance length, and y = tip amount
By using data on your tips from the past to hypothesize your future tips, you're thinking like a statistician.
As you mature in your drag career, you may learn that tip amounts aren’t so predictable. Some nights your 2 minute song will get 20 dollars, and on other nights it’ll get 25.
There’s some element of randomness that makes each performance different.
After 10 performances, your scatterplot might look like like this.

The data still resembles somewhat of a straight line, but it's no longer possible to draw a single line that passes through every point. Drawing the same line as we had before is sure to miss some points.

The goal of linear regression is to draw a line of "best fit". That is, a line that best represents the overall trend, by being as close as possible to all the data points.
Let's update the plot with a line that fits better.
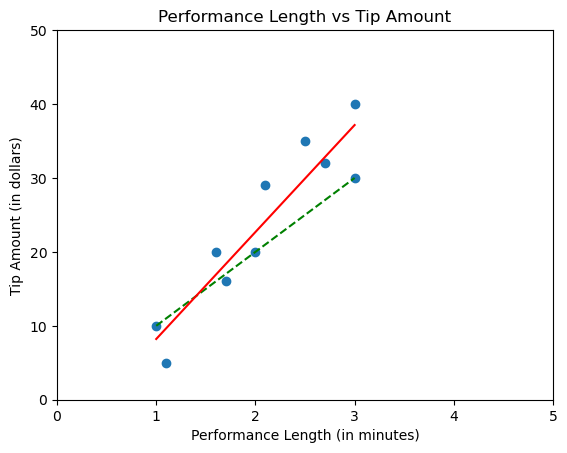
Finding the line of best fit is the goal of linear regression.
Imagine that this dataset actually represents a totally different scenario, like a baby's head circumference and gestational age, or the number of cars on the road and the rate of car accidents, or a person's salt consumption and blood pressure.
The role of a statistician is to develop a model that represents broad patterns in the data, and use that model to make useful predictions.
We want to draw the best possible line of best fit, to make the model as accurate as possible!
By "model", I'm referring to our line of best fit. That's our model! By fitting it to our dataset, we're "training" it on past data, and we can use it to extrapolate to future performances. That's why linear regression may be considered a form of machine learning!
But how do we find the line of best fit?
How do we know that the solid red line is a better fit than the dashed green line? What if it was possible to draw an even better line?
It would be great if there was a numerical "measure" we could use to rank how good each line is, so we could compare the two.
To rank how well a line fits the data, you could look at all the data points which are not on the line, and then measure how far away from the line they are.
We call this a loss function, because it measures how much our line misses the data points.
Sum of Squares of Errors
To measure how well or how poorly our line fits the data, we might start by adding up the distances between each data point and the line.
The data points are represented by y, and the equation of the line is mx + b.
Some data points will be above the line and others will be below, but we don't want the positive and negative distances to cancel each other out, so we'll square each distance to keep it non-negative, and then add up all these distances.
We call this equation the Sum of Squares of Errors
Let's compute the SSE of the dashed green line.

SSE = 342
The dashed red lines represent the errors, and we square each one to keep it from being negative, and add them all up. (To see this calculation along with the code behind these plots, I’ve put it on github!)
We get SSE = 342. How well does our other line do?

SSE = 156.71, which is a lot better!
But how do we know this is the best possible line we can get? Is it possible to get this SSE even smaller?
Sounds like calculus!
In calculus class, you may have learned about finding the minimum of a function, by taking the derivative and solving for when the derivative equals zero.
Let's look at the formula for SSE again:
In this equation, we can't control the values of 𝑦𝑖 and 𝑥𝑖, but we can control the parameters 𝑚 and 𝑏.
So SSE is really a function of two variables: 𝑚 and 𝑏. That means we can't plot it as a line, but rather as a surface in a 3D plot! How exciting!

To find the minimum value of SSE, we can take the partial derivates of the SSE function with respect to 𝑚 and 𝑏, and that's how we can find the line of best fit.
Now you have a better understanding of what linear regression is all about.
After perfecting your model, maybe you get cocky and start performing really long songs to get as many tips as possible, but you find that your tips don’t get much better. After the 3rd chorus, you've collected as many tips as you're going to get, so your line starts to plateau.
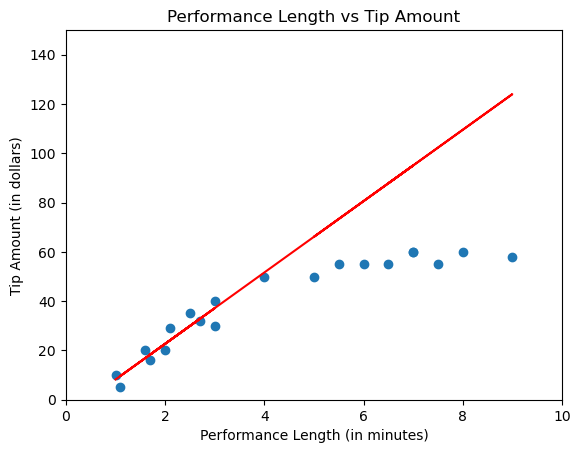
In light of this new information, our previous line of best fit doesn't look like it fits very well anymore.
Maybe you decide you want to update your model and draw a new line.
Perhaps you decide that the new model should actually be a curve, instead of a straight line.
Or, maybe you want to add more variables, because you think that your tips might also affected by the day of the week and the size of the audience, and the type of performance (ballad, dance, comedy).
All of these are things we can add to our linear regression model. With the single variable (performance length), the model is called 𝑠𝑖𝑚𝑝𝑙𝑒 𝑙𝑖𝑛𝑒𝑎𝑟 𝑟𝑒𝑔𝑟𝑒𝑠𝑠𝑖𝑜𝑛. If we use multiple variables (performance length, day of the week, audience size, performance type), it's called 𝑚𝑢𝑙𝑡𝑖𝑝𝑙𝑒 𝑙𝑖𝑛𝑒𝑎𝑟 𝑟𝑒𝑔𝑟𝑒𝑠𝑠𝑖𝑜𝑛. If we want to plot all of this a scatterplot, we would need a 5-dimensional plot!
Sadly, there aren't enough dimensions in our universe. But we can still use linear regression, even if we can't visualize the line of best fit anymore! That's why we eventually have to rely on numerical measures like SSE to tell us when a line is a good fit -- we can't see a line in 5 dimensions!
All this just for some tip money at a drag show?

Even when the data gets complex, statistics can rise to meet the challenge. When our models are good, our predictions are good. And by minimizing the errors, we can make important and useful predictions, in matters of health care, public policy, life, death, and drag.
As part of my studying, I’m also teaching myself Python! You can see the code for this entire blogpost here. I’m a newbie to Python and github, so feel free to roast me, I’m open to learning more!
Let me know if you have any questions. Or what mathematical/statistical concepts would you like to see explained next?